Comparing DDL and NCCL horovod performance
My preferred framework for distributed machine learning is Horovod. Horovod makes it simple to process multiple batches batches of data across multiple compute nodes with minimal code changes, and it works with multiple libraries. The communication is fairly lightweight since it only broadcasts updates and aggregates losses, so the speedup is almost linear.
The official Horovod documentation recommends using NVIDIA’s Collective Communications Library (NCCL) for distributed operations across GPUs. Since NVIDIA acquired Mellanox, Infiniband is now one of their products, so their own libraries should be performant. However, IBM recommends using their Distributed Deep Learning (DDL) library, so I wanted to compare the performance between the two.
My tests will take place on the Longhorn supercomputer at the Texas Advanced Computing Center, with 108 compute nodes each configured as follows:
| Component | Description |
|---|---|
| Model | IBM Power System AC922 (8335-GTH) |
| Processor | IBM Power 9 |
| Total processors per node | 2 |
| Total cores per processor | 20 |
| RAM | 256GB |
| Local storage | ~900 GB (/tmp) |
| GPUs | 4x NVIDIA Tesla V100 |
| GPU RAM | 4x 16GB (64 GB aggregate) |
To compare the NCCL and DDL communication libraries, two separate conda environment were created. Longhorn is an IBM PowerAI system, so packages from the IBM WML repository were given priority. Each environment shared the following package requirements:
- Python 3
- TensorFlow 2.1
- CUDA 10.2
- Spectrum MPI
Starting with PowerAI 1.7.0, IBM started serving Horovod built for DDL, so only ddl and horovod were added as requirements for the DDL environment.
To compile Horovod with pip, the NCCL environment required gxx_linux-ppc64le, cffi, and nccl.
# IBM WML conda repository
WML=https://public.dhe.ibm.com/ibmdl/export/pub/software/server/ibm-ai/conda/
# Create DDL environment
$ conda create -n ddl -c $WML -c defaults \
python=3 tensorflow-gpu=2.1 cudatoolkit=10.2 spectrum-mpi \
ddl horovod
# Create NCCL environment
$ conda create -n nccl -c $WML -c defaults \
python=3 tensorflow-gpu=2.1 cudatoolkit=10.2 spectrum-mpi \
cffi gxx_linux-ppc64le nccl
$ conda activate nccl
# Compile and install horovod via pip
(nccl)$ HOROVOD_CUDA_HOME=$CONDA_PREFIX \
HOROVOD_GPU_BROADCAST=NCCL \
HOROVOD_GPU_ALLREDUCE=NCCL \
pip install horovod --no-cache-dir
# Clean up environment
(nccl)$ conda deactivate
I then downloaded the TensorFlow Benchmark suite and checked out the branch with TensorFlow 2.1 compatibility.
$ git clone --branch cnn_tf_v2.1_compatible https://github.com/tensorflow/benchmarks.git
$ cd benchmarks
While the environment were created on the login nodes,
I then allocated 6 compute nodes -N 6 for 30 minutes -m 30, with 1 task per gpu, 4 gpus per node, and 24 tasks total -n 24, on the normal v100 queue -p v100.
$ idev -N 6 -n 24 -m 30 -p v100
TACC uses SLURM for scheduling jobs, but idev is the recommended way to schedule interactive jobs.
Once the nodes were allocated, tested TensorFlow performance in each environment on:
- single-node execution using 1 and 4 GPUs
- multi-node execution with Horovod using 1, 2, 4, and 6 nodes
#!/bin/bash
# Target benchmark script
PF=scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py
# Benchmark arguments
ARGS="--model resnet50 --batch_size 32 --num_batches 100"
# Benchmark arguments when using horovod
HARGS="$ARGS --variable_update=horovod"
# Get node names in job
NL=$(echo $(scontrol show hostname $SLURM_NODELIST) | tr ' ' ',')
# Recommended DDL argument
DDLARG="-x HOROVOD_FUSION_THRESHOLD=16777216"
##################################
# NCCL runs
##################################
# Activate nccl environment
conda activate nccl
# Run single-node tests
for i in {1..4}; do
python $PF --num_gpus=$i $ARGS > nccl_g${i}.txt
done
# Export horovod argument recommended by DDL
export HOROVOD_FUSION_THRESHOLD=16777216
# Run multi-node tests for 1,2,4,6 nodes
for i in 4 8 16 24; do
ibrun -n $i python $PF --num_gpus=1 $HARGS > nccl_g${i}_horovod.txt
done
# Clean up environment
unset HOROVOD_FUSION_THRESHOLD
conda deactivate
##################################
# DDL runs
##################################
# Activate DDL environment
conda activate ddl
# Run single-node tests
for i in {1..4}; do
python $PF --num_gpus=$i $ARGS > ddl_g${i}.txt
done
# Run multi-node tests for 1,2,4,6 nodes
for N in 1 2 4 6; do
ddlrun -H $(echo $NL | cut -d ',' -f 1,$N) -mpiarg "$DDLARG" python $PF --num_gpus=1 $HARGS >
_g$(($N*4))_horovod.txt
done
# Clean up environment
conda deactivate
Results were written to the following files:
- Single-node - {ddl,nccl}_g{1,4}.txt
- Multi-node - {ddl,nccl}_g{4,8,16,24}_horovod.txt
Performance was measured in images per second. Since each worker reports their own classification rate, you can extract the aggregate total performance with the following grep command.
grep -H "total " -m 1 {nccl,ddl}*.txt
Single-Node Results
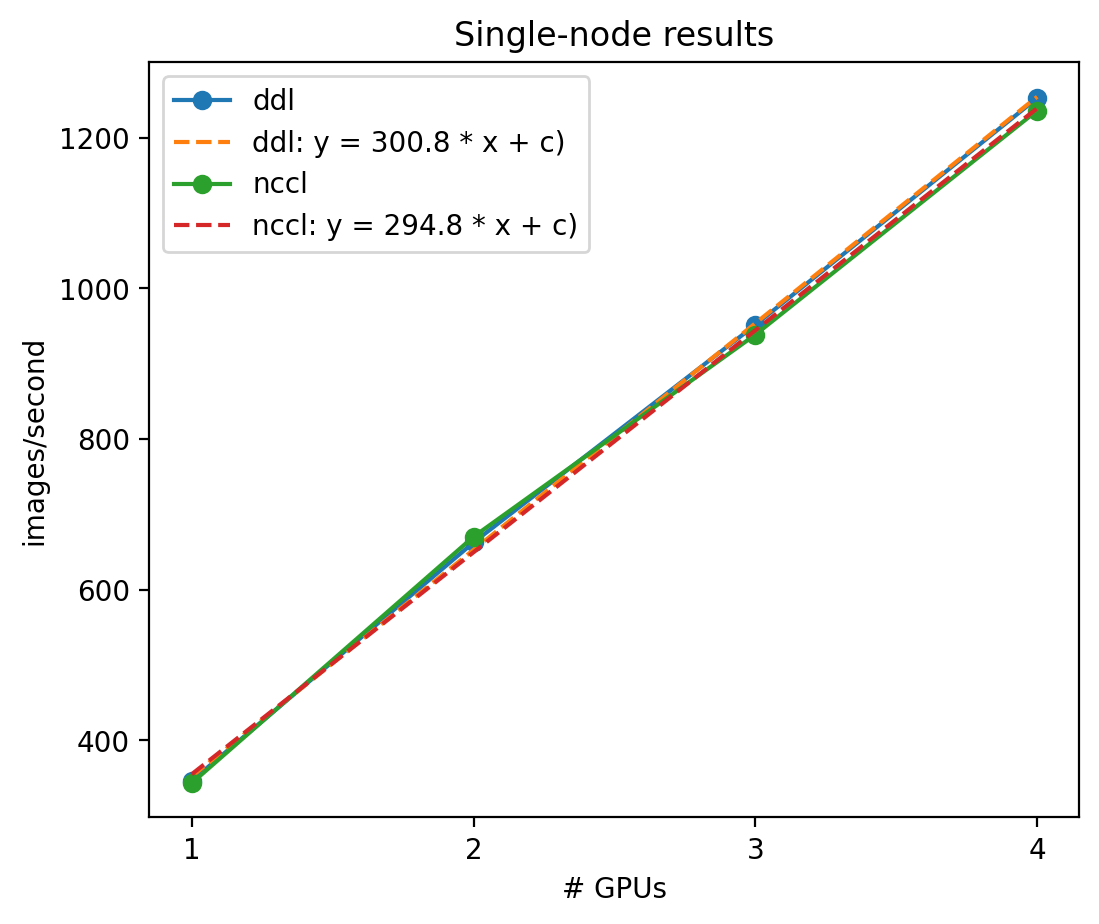
Results showed that single-node performance scaled linearly, and a linear regression found that the NCCL environment processed 295 images/second/gpu and the DDL environment processed 301 images/second/gpu. Even though horovod was not explicitly specified for the update method, the environment with DDL was 2% faster.
\[\frac{300.8-294.8}{294.8} * 100 = 2.04\%\]Multi-Node Results
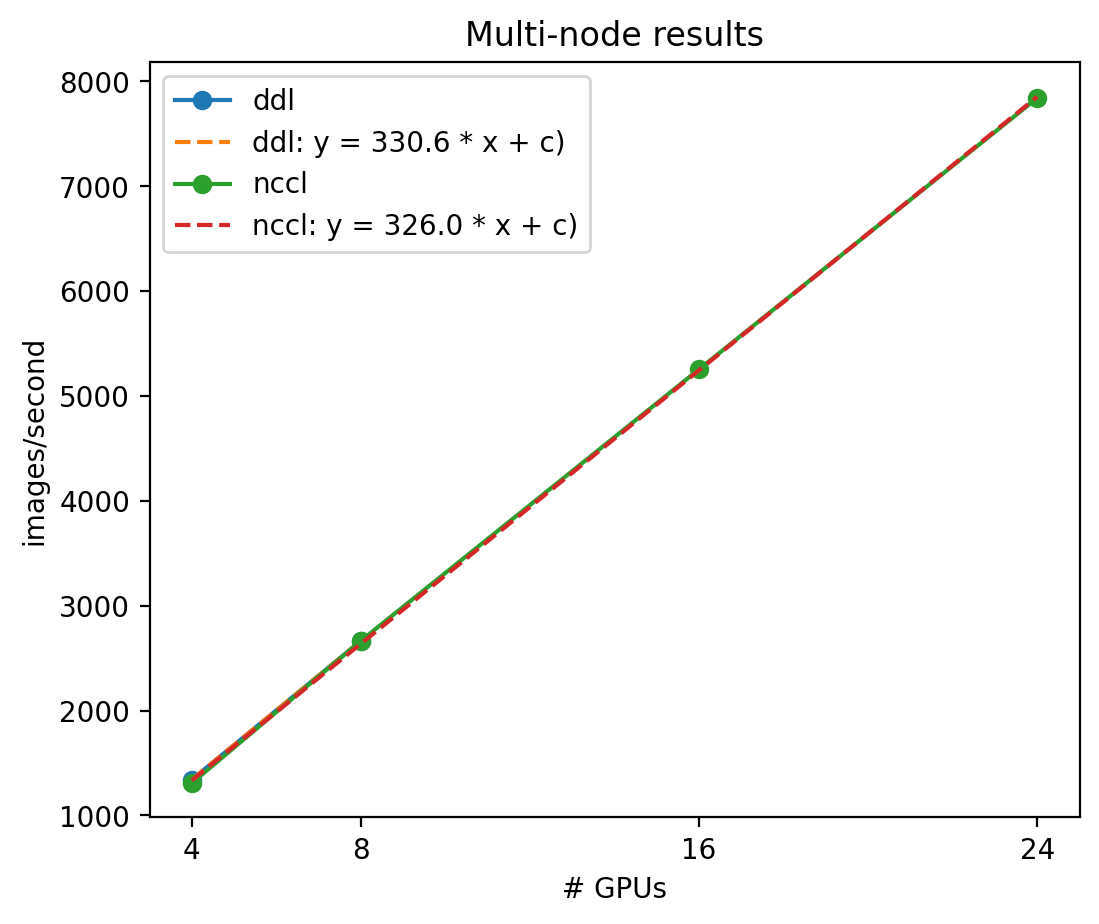
Since the DDL environment could only be evaluated on a maximum of 2 nodes, I assumed it would scale linearly as the NCCL environment did. Another linear regression found that the NCCL environment processed 326 images/second/gpu while the DDL environment processed 331 images/second/gpu. The classification throughput for both environments was faster when using Horovod for batch distribution, and once again the DDL environment was 1.4% faster than NCCL.
\[\frac{330.6-326}{326} * 100 = 1.4\%\]Conclusions
Even though the DDL environment was faster than the NCCL environment for both single- and multi-node tests, it was at most 2% faster. If you need official support and the most speed possible, you may want to purchase a DDL license from IBM. Otherwise, relying on NCCL from NVIDIA will work fine without significant performance loss, even as you scale across nodes.
13 May 2020