Mitigating a memory leak in Tensorflow's LSTM
I have been running a parameter sweep on a recurrent neural network (RNN) consisting of long short-term memory (LSTM) layers, and most of my long runs would eventually fail after being able to allocate additional memory.
OSError: [Errno 12] Cannot allocate memory
My jobs would run fine for several hours and then suddenly fail even though the batch size stayed constant. The jobs usually started with about 30% of the memory free (20GB), so some operation was definitely leaking memory. The TensorFlow issue tracker had 3 reported issues concerning LSTMs and memory leaks:
- Memory leak when training simple LSTM Network
- Running TF 1.14.0
- CLOSED after reporting “upgraded to TF2.0 and the issue went away.”
- Keras 2.2.4 Leaks Memory when using TensorFlow 2.0.0
- Running TF 2.0.0
- CLOSED after mitigating with
tf.keras.backend.clear_session()and/or replacing.fit()with.train_on_batch()
- Potential memory leak when using LSTM + TimeDistributed
- Running TF 2.0.0 + GPU
- OPEN but reported to be fixed in 2.0.0 beta1
My jobs were running TensorFlow 1.14.0 from anaconda, so I decided to compile and test
- TF 1.15.0 + mkl-dnn 0.20.3 (default)
- TF 1.15.0 + mkl-dnn 0.21.2 (manually upgraded)
While v2.0.0 did hit stable, I decided to not test it since the breaking changes would require significant changes to my code, and issue #33178 was still open.
After the long process of compiling both of these versions of TF 1.15, both versions continuously increased in memory while running. This meant I needed to not only rule out the possibility that my model was the culprit, and determine if any runtime configurations could have an effect since there were conflicting reports on the issue threads.
Example Model
I have a “dishonest casino” sequential data example that I like to use for RNNs, which switches between fair and loaded 4-sided dice (d4).
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, TimeDistributed, Dense
from tensorflow.keras.optimizers import Adam
import resource
# Class for generating input and output data
class d4:
def __init__(self):
fair = np.ones(4)/4.0
load = np.array([0.5, 0.3, 0.2, 0.0])
self.dice = np.vstack((fair, load))
def roll_gen(self, n):
x, y = np.zeros((n,1), dtype=np.uint8), np.zeros((n,1), dtype=np.uint8)
y[0] = np.random.choice(2)
for i in range(n):
x[i] = np.random.choice(4, replace=True, p=self.dice[y[i,0],:])
if i < n-1:
# Switch die after seeing two 1s
if i >= 1 and np.all(x[i-1:i+1] == 1):
y[i+1] = 1 - y[i]
else:
y[i+1] = y[i]
return x, y
def roll_batch(self, n, b):
x,y = np.zeros((b,n,1), dtype=np.uint8), np.zeros((b,n,1), dtype=np.uint8)
for i in range(b):
tx, ty = self.roll_gen(n)
x[i,:,:] = tx
y[i,:,:] = ty
return x,y
# Helper function for creating model
def gen_model(n):
model = Sequential()
model.add(LSTM(128, return_sequences=True, input_shape=(n,1)))
model.add(TimeDistributed(Dense(1, activation='linear')))
model.compile(loss='mean_squared_error', optimizer=Adam())
return model
# Initialize model and data
seq_len, batch_size, batches = 200, 200, 20
casino = d4()
model = gen_model(seq_len)
mem = np.zeros(batches+1)
mem[0] = resource.getrusage(resource.RUSAGE_SELF).ru_maxrss
# Run model
for e in range(batches):
xb, yb = casino.roll_batch(seq_len, batch_size)
loss = model.train_on_batch(xb, yb)
kb = resource.getrusage(resource.RUSAGE_SELF).ru_maxrss
print "batch %02i - Max res size: %.0f MB Change res size: %.2f MB Loss: %.3f"%(e+1, kb/1000.0, (kb-mem[e])/1000.0, loss)
mem[e+1] = kb
The d4 class generates both the sequences and batches of rolls, along with the known classification tags.
The gen_model() function generates and returns the constructed and compiled Keras model.
In between training separate batches, resource.getrusage() is used to print the maximum resident memory size.
Running this script on TF 1.15.0 + mkl-dnn 0.21.2 yielded the following output
batch 01 - Max res size: 823 MB Change res size: 612.84 MB Loss: 0.402
batch 02 - Max res size: 873 MB Change res size: 50.11 MB Loss: 0.330
batch 03 - Max res size: 895 MB Change res size: 21.63 MB Loss: 0.323
batch 04 - Max res size: 900 MB Change res size: 5.12 MB Loss: 0.328
batch 05 - Max res size: 906 MB Change res size: 6.40 MB Loss: 0.335
batch 06 - Max res size: 910 MB Change res size: 3.57 MB Loss: 0.316
batch 07 - Max res size: 915 MB Change res size: 5.01 MB Loss: 0.305
batch 08 - Max res size: 923 MB Change res size: 8.08 MB Loss: 0.293
batch 09 - Max res size: 926 MB Change res size: 3.75 MB Loss: 0.277
batch 10 - Max res size: 931 MB Change res size: 4.62 MB Loss: 0.278
batch 11 - Max res size: 936 MB Change res size: 4.96 MB Loss: 0.278
batch 12 - Max res size: 940 MB Change res size: 4.46 MB Loss: 0.265
batch 13 - Max res size: 945 MB Change res size: 4.70 MB Loss: 0.256
batch 14 - Max res size: 953 MB Change res size: 8.21 MB Loss: 0.239
batch 15 - Max res size: 958 MB Change res size: 4.30 MB Loss: 0.232
batch 16 - Max res size: 962 MB Change res size: 4.42 MB Loss: 0.222
batch 17 - Max res size: 969 MB Change res size: 6.60 MB Loss: 0.211
batch 18 - Max res size: 974 MB Change res size: 5.48 MB Loss: 0.202
batch 19 - Max res size: 977 MB Change res size: 3.17 MB Loss: 0.188
batch 20 - Max res size: 982 MB Change res size: 4.47 MB Loss: 0.180
As indicated by the “Change res size” column, the memory continued to increase after processing each batch.
Issue #32954 reported that the memory leak was circumvented when not using the normal Model.fit() function, so these are conflicting results since this code used Model.train_on_batch().
Issue #33178 reported that the TimeDistributed wrapper was the culprit, but both the LSTM and TimeDistribute layers must both be present to generate correct output, which confounds this association.
To identify which layer had the most significant effect on the memory loss, I created two more models with an additional layer of each type.
Another LSTM layer
def gen_model(n):
model = Sequential()
model.add(LSTM(128, return_sequences=True, input_shape=(n,1)))
+ model.add(LSTM(128, return_sequences=True))
model.add(TimeDistributed(Dense(1, activation='linear')))
model.compile(loss='mean_squared_error', optimizer=Adam())
return model
Another TimeDistributed layer
def gen_model(n):
model = Sequential()
model.add(LSTM(128, return_sequences=True, input_shape=(n,1)))
+ model.add(TimeDistributed(Dense(128, activation='tanh')))
model.add(TimeDistributed(Dense(1, activation='linear')))
model.compile(loss='mean_squared_error', optimizer=Adam())
return model
After collecting both the cumulative and differential memory usage by batch number, all three architectures were plotted for visual comparison.
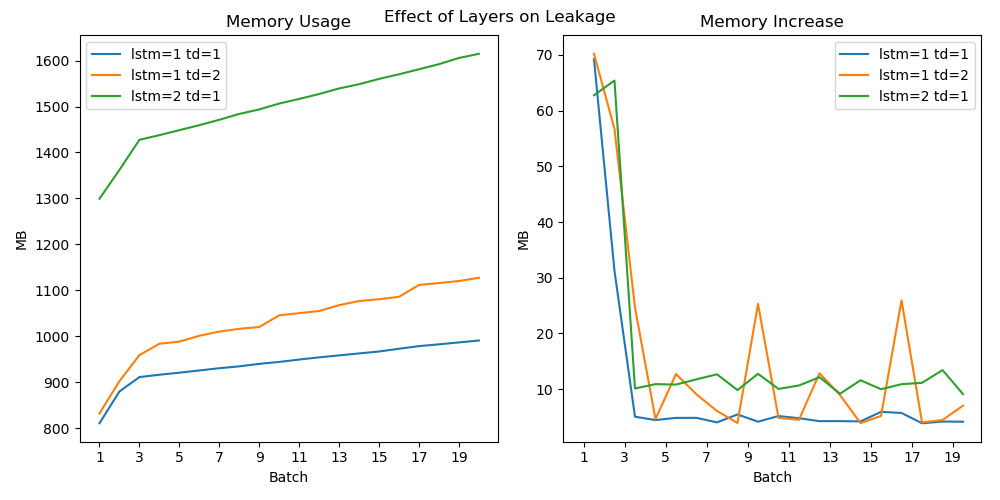
On the left, both adding another time distributed (gold) and LSTM (green) layers increased the overall memory usage, but the additional LSTM layer took up 50% more initial memory. The right plot shows that the time distributed layer sporadically increased the memory with time, while the LSTM layer consumed additional memory at a higher, constant rate. This told me that they both contributed to the leak, but the LSTM layer tended to be more complex and regularly ate memory faster.
Attempting to mitigate the problem
Since I know that the memory leak appears in the simplest of models, I can assume that the core LSTM cell or layer is the problem. However, investigating and modifying the Keras, TensorFlow, MKL, and/or mkl-dnn code is beyond my expertise and available time. Since there are conflicting reports in the issue threads, I will hope that some specific run configurations which do not trigger the memory leak exist.
I have some prior experience experimenting with session configurations and runtime flags to optimize runtime and fix memory errors. Based on what I know had an effect in those domains, I will be trying:
Configuring session threads
from tensorflow.keras.backend import set_session config = tensorflow.ConfigProto(intra_op_parallelism_threads=24, inter_op_parallelism_threads=2) set_session(tensorflow.Session(config=config))
Disabling arithmetic optimization
from tensorflow.keras.backend import set_session from tensorflow.core.protobuf import rewriter_config_pb2 config = tensorflow.ConfigProto(intra_op_parallelism_threads=24, inter_op_parallelism_threads=2) off = rewriter_config_pb2.RewriterConfig.OFF config.graph_options.rewrite_options.arithmetic_optimization = off set_session(tensorflow.Session(config=config))This solved previous memory allocation errors with large models.
Enabling XLA JIT
$ TF_XLA_FLAGS="--tf_xla_auto_jit=2 --tf_xla_cpu_global_jit" python script.pyEnabling XLA auto-clustering improves performance in some cases.
Disabling MKL-DNN
$ TF_DISABLE_MKL=1 python script.pyThis flag only disables the MKL-DNN and leaves the MKL enabled for accelerating normal linear algebra calls. I have found that the MKL-DNN increases performance of single-node workloads, but sometimes causes issues with Horovod, so I disable it on distributed runs.
I also included the median rate that batches were processed (seq/second) was also included in the output of these tests for another comparison metric.
Results
Results were compounded into a Markdown table by the script gen_table.py.
| DNN | XLA | Config | ArithOpt | Min | Q1 | Median | Q3 | Max | median(Rate) |
|---|---|---|---|---|---|---|---|---|---|
| on | on | default | on | 108 | 416 | 712 | 1626 | 3104 | 273 |
| on | on | custom | on | 0 | 0 | 88 | 222 | 4860 | 259 |
| on | on | custom | off | 0 | 0 | 4 | 94 | 3764 | 257 |
| on | off | default | on | 3396 | 4084 | 4792 | 5840 | 65176 | 684 |
| on | off | custom | on | 4352 | 4600 | 4780 | 4984 | 12664 | 408 |
| on | off | custom | off | 3740 | 3998 | 4092 | 4322 | 13980 | 393 |
| off | on | default | on | 0 | 0 | 0 | 91112 | 194316 | 256 |
| off | on | custom | on | 0 | 0 | 0 | 4472 | 53960 | 273 |
| off | on | custom | off | 0 | 0 | 0 | 0 | 96744 | 271 |
| off | off | default | on | 0 | 0 | 2624 | 16294 | 149888 | 990 |
| off | off | custom | on | 0 | 0 | 0 | 0 | 15428 | 473 |
| off | off | custom | off | 0 | 0 | 0 | 0 | 10920 | 477 |
Table 1 - Memory values are in kilobytes, and the median processing rate is in sequences per second.
This table shows the following trends:
- Setting the ConfigProto usually results in a reduced rate of memory usage.
- DNN without XLA is the exception
- Automatic defaults may be unsuitable for a 2x12-core systems.
- Whenever the MKL-DNN is enabled there is a slight memory leak. This can be mitigated by:
- Enabling XLA and setting the ConfigProto to reflect the system (runs slower)
- When not using the MKL-DNN, there is no memory leak when
- Not using XLA (faster)
- Setting the ConfigProto to reflect your system (defaults are bad)
These conclusions can be tested on the larger model with 2 LSTM and 2 TimeDistributed layers to see if the memory leak is indeed reduced.
DNN+XLA+Custom Results
batch 01 - Max res size: 1256 MB Change res size: 1040.81 MB Loss: 0.379 Rate: 34.7 seq/s
batch 02 - Max res size: 1256 MB Change res size: 0.91 MB Loss: 0.321 Rate: 126.7 seq/s
batch 03 - Max res size: 1257 MB Change res size: 0.33 MB Loss: 0.329 Rate: 124.8 seq/s
batch 04 - Max res size: 1257 MB Change res size: 0.08 MB Loss: 0.310 Rate: 132.2 seq/s
batch 05 - Max res size: 1257 MB Change res size: 0.06 MB Loss: 0.298 Rate: 131.5 seq/s
batch 06 - Max res size: 1396 MB Change res size: 139.26 MB Loss: 0.294 Rate: 130.9 seq/s
batch 07 - Max res size: 1396 MB Change res size: 0.00 MB Loss: 0.278 Rate: 128.7 seq/s
batch 08 - Max res size: 1396 MB Change res size: 0.00 MB Loss: 0.260 Rate: 135.7 seq/s
batch 09 - Max res size: 1396 MB Change res size: 0.00 MB Loss: 0.248 Rate: 129.8 seq/s
batch 10 - Max res size: 1396 MB Change res size: 0.00 MB Loss: 0.237 Rate: 129.5 seq/s
batch 11 - Max res size: 1396 MB Change res size: 0.00 MB Loss: 0.223 Rate: 128.5 seq/s
batch 12 - Max res size: 1396 MB Change res size: 0.00 MB Loss: 0.210 Rate: 126.3 seq/s
batch 13 - Max res size: 1396 MB Change res size: 0.00 MB Loss: 0.194 Rate: 131.9 seq/s
batch 14 - Max res size: 1396 MB Change res size: 0.00 MB Loss: 0.181 Rate: 127.9 seq/s
batch 15 - Max res size: 1396 MB Change res size: 0.00 MB Loss: 0.176 Rate: 132.0 seq/s
batch 16 - Max res size: 1396 MB Change res size: 0.00 MB Loss: 0.186 Rate: 130.8 seq/s
batch 17 - Max res size: 1396 MB Change res size: 0.00 MB Loss: 0.170 Rate: 129.5 seq/s
batch 18 - Max res size: 1396 MB Change res size: 0.00 MB Loss: 0.175 Rate: 122.8 seq/s
batch 19 - Max res size: 1396 MB Change res size: 0.00 MB Loss: 0.171 Rate: 131.3 seq/s
batch 20 - Max res size: 1396 MB Change res size: 0.00 MB Loss: 0.163 Rate: 134.1 seq/s
Custom Results
batch 01 - Max res size: 1154 MB Change res size: 942.00 MB Loss: 0.405 Rate: 77.3 seq/s
batch 02 - Max res size: 1154 MB Change res size: 0.00 MB Loss: 0.311 Rate: 218.3 seq/s
batch 03 - Max res size: 1154 MB Change res size: 0.00 MB Loss: 0.339 Rate: 203.5 seq/s
batch 04 - Max res size: 1168 MB Change res size: 13.18 MB Loss: 0.331 Rate: 158.7 seq/s
batch 05 - Max res size: 1168 MB Change res size: 0.00 MB Loss: 0.308 Rate: 218.8 seq/s
batch 06 - Max res size: 1201 MB Change res size: 33.27 MB Loss: 0.285 Rate: 222.3 seq/s
batch 07 - Max res size: 1201 MB Change res size: 0.00 MB Loss: 0.288 Rate: 216.3 seq/s
batch 08 - Max res size: 1201 MB Change res size: 0.00 MB Loss: 0.298 Rate: 206.2 seq/s
batch 09 - Max res size: 1201 MB Change res size: 0.00 MB Loss: 0.285 Rate: 200.6 seq/s
batch 10 - Max res size: 1201 MB Change res size: 0.00 MB Loss: 0.268 Rate: 211.9 seq/s
batch 11 - Max res size: 1201 MB Change res size: 0.00 MB Loss: 0.256 Rate: 217.6 seq/s
batch 12 - Max res size: 1201 MB Change res size: 0.00 MB Loss: 0.252 Rate: 211.0 seq/s
batch 13 - Max res size: 1201 MB Change res size: 0.00 MB Loss: 0.249 Rate: 217.1 seq/s
batch 14 - Max res size: 1201 MB Change res size: 0.00 MB Loss: 0.239 Rate: 215.6 seq/s
batch 15 - Max res size: 1201 MB Change res size: 0.00 MB Loss: 0.222 Rate: 207.6 seq/s
batch 16 - Max res size: 1201 MB Change res size: 0.00 MB Loss: 0.208 Rate: 203.9 seq/s
batch 17 - Max res size: 1201 MB Change res size: 0.00 MB Loss: 0.203 Rate: 221.0 seq/s
batch 18 - Max res size: 1201 MB Change res size: 0.00 MB Loss: 0.196 Rate: 232.5 seq/s
batch 19 - Max res size: 1201 MB Change res size: 0.00 MB Loss: 0.178 Rate: 220.4 seq/s
batch 20 - Max res size: 1201 MB Change res size: 0.00 MB Loss: 0.180 Rate: 225.0 seq/s
These results show that both versions of the larger model stop increasing in memory usage after the first couple batches, but it may be best to run LSTM models without the Intel MKL-DNN
$ TF_DISABLE_MKL=1 python script.py
and explicitly setting your ConfigProto
from tensorflow.keras.backend import set_session
config = tensorflow.ConfigProto(intra_op_parallelism_threads=24, inter_op_parallelism_threads=2)
set_session(tensorflow.Session(config=config))
for the best throughput. I am running on a 2x12-core Haswell system, so results may vary and I suggest you test both configurations.
Additional results on Anaconda TF 1.14 + MKL
Since compiling Tensorflow with the latest MKL-DNN is a pain, I also wanted to show the resulting metrics from the stable release from Anaconda.
| DNN | XLA | Config | ArithOpt | Min | Q1 | Median | Q3 | Max | median(Rate) |
|---|---|---|---|---|---|---|---|---|---|
| on | on | default | on | 0 | 1946 | 2044 | 2328 | 2632 | 313 |
| on | on | custom | on | 340 | 1930 | 2048 | 2188 | 2552 | 314 |
| on | on | custom | off | 0 | 0 | 8 | 32 | 832 | 324 |
| on | off | default | on | 4268 | 4614 | 4776 | 5236 | 25028 | 245 |
| on | off | custom | on | 4188 | 4526 | 4684 | 5066 | 6992 | 247 |
| on | off | custom | off | 3696 | 3906 | 4116 | 4622 | 7024 | 241 |
| off | on | default | on | 0 | 0 | 0 | 256 | 172480 | 344 |
| off | on | custom | on | 0 | 0 | 0 | 0 | 53428 | 324 |
| off | on | custom | off | 0 | 0 | 0 | 500 | 64024 | 314 |
| off | off | default | on | 0 | 0 | 29404 | 34590 | 111068 | 329 |
| off | off | custom | on | 0 | 0 | 0 | 0 | 11248 | 262 |
| off | off | custom | off | 0 | 0 | 0 | 0 | 10900 | 281 |
Table 2 - Memory values are in kilobytes, and the median processing rate is in sequences per second.
Based on this table, it looks like the XLA has a larger effect on the performance than the DNN. With that said, I would recommend
- disabling the DNN and enabling XLA JIT
-
$ TF_DISABLE_MKL=1 TF_XLA_FLAGS="--tf_xla_auto_jit=2 --tf_xla_cpu_global_jit" python script.py
-
- defining a custom ConfigProto
-
from tensorflow.keras.backend import set_session config = tensorflow.ConfigProto(intra_op_parallelism_threads=24, inter_op_parallelism_threads=2) set_session(tensorflow.Session(config=config))
-
to yield the best performance and memory efficiency for LSTM models.
Raw testing code and results available in rnn_memory_leak.tar.gz
Additional results on Anaconda TF 2.0.0 + MKL
| DNN | XLA | Config | ArithOpt | Min | Q1 | Median | Q3 | Max | median(Rate) |
|---|---|---|---|---|---|---|---|---|---|
| on | on | default | on | 0 | 26054 | 49176 | 51200 | 315692 | 147 |
| on | on | custom | on | 60 | 26490 | 49156 | 51210 | 315124 | 147 |
| on | on | custom | off | 4 | 26064 | 49168 | 51200 | 314016 | 148 |
| on | off | default | on | 0 | 24756 | 51172 | 51210 | 313808 | 148 |
| on | off | custom | on | 12 | 24826 | 49156 | 51202 | 313720 | 154 |
| on | off | custom | off | 4 | 26194 | 50596 | 51200 | 313828 | 148 |
| off | on | default | on | 50180 | 50732 | 51832 | 53918 | 74776 | 473 |
| off | on | custom | on | 49388 | 50264 | 51460 | 54454 | 70060 | 492 |
| off | on | custom | off | 49604 | 50588 | 51016 | 53692 | 77564 | 486 |
| off | off | default | on | 49428 | 50452 | 51112 | 54184 | 72856 | 488 |
| off | off | custom | on | 48868 | 51340 | 52108 | 53736 | 71092 | 483 |
| off | off | custom | off | 49936 | 51146 | 51440 | 55436 | 76740 | 487 |
These results have prompted me to move away from running LSTMs on CPUs.
Updated code for TF 2.0.0
import numpy as np
import tensorflow
from tensorflow.core.protobuf import rewriter_config_pb2
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, TimeDistributed, Dense
from tensorflow.keras.optimizers import Adam
import resource, pprint, sys, os
from time import time
dnn, xla, c, opt = 'on', 'off', 'default', 'on'
if 'TF_XLA_FLAGS' in os.environ:
xla = 'on'
if 'TF_DISABLE_MKL' in os.environ:
dnn = 'off'
if len(sys.argv) > 1 and sys.argv[1] == 'custom':
c = 'custom'
tensorflow.config.threading.set_intra_op_parallelism_threads(24)
tensorflow.config.threading.set_inter_op_parallelism_threads(2)
if len(sys.argv) > 2 and sys.argv[2] == 'arith':
opt = 'off'
off = rewriter_config_pb2.RewriterConfig.OFF
tensorflow.config.optimizer.set_experimental_options({'arithmetic_optimization':off})
suff = 'dnn-%s_xla-%s_c-%s_opt-%s'%(dnn, xla, c, opt)
# Class for generating input and output data
class d4:
def __init__(self):
fair = np.ones(4)/4.0
load = np.array([0.5, 0.3, 0.2, 0.0])
self.dice = np.vstack((fair, load))
def roll_gen(self, n):
x, y = np.zeros((n,1), dtype=np.uint8), np.zeros((n,1), dtype=np.uint8)
y[0] = np.random.choice(2)
for i in range(n):
x[i] = np.random.choice(4, replace=True, p=self.dice[y[i,0],:])
if i < n-1:
if i >= 1 and np.all(x[i-1:i+1] == 1):
y[i+1] = 1 - y[i]
else:
y[i+1] = y[i]
return x, y
def roll_batch(self, n, b):
x,y = np.zeros((b,n,1), dtype=np.uint8), np.zeros((b,n,1), dtype=np.uint8)
for i in range(b):
tx, ty = self.roll_gen(n)
x[i,:,:] = tx
y[i,:,:] = ty
return x,y
# Helper function for creating model
def gen_model(n):
model = Sequential()
model.add(LSTM(128, return_sequences=True, input_shape=(n,1)))
#model.add(LSTM(128, return_sequences=True))
#model.add(TimeDistributed(Dense(128, activation='tanh')))
model.add(TimeDistributed(Dense(1, activation='linear')))
model.compile(loss='mean_squared_error', optimizer=Adam())
return model
# Initialize model and data
seq_len = 200
batch_size = 500
epochs = 20
casino = d4()
model = gen_model(seq_len)
mem = np.zeros(epochs+1)
rateA = np.zeros(epochs)
mem[0] = resource.getrusage(resource.RUSAGE_SELF).ru_maxrss
# Run model
for e in range(epochs):
xb, yb = casino.roll_batch(seq_len, batch_size)
start = time()
loss = model.train_on_batch(xb, yb)
elapsed = time()-start
rate = float(batch_size)/elapsed
kb = resource.getrusage(resource.RUSAGE_SELF).ru_maxrss
print "batch %02i - Max res size: %.0f MB Change res size: %.2f MB Loss: %.3f Rate: %.1f seq/s "%(e+1, kb/1000.0, (kb-mem[e])/1000.0, loss, rate)
mem[e+1] = kb
rateA[e] = rate
with open('mem_%s.tsv'%(suff),'w') as OF:
for m in mem: OF.write('%f\n'%(m))
with open('rate_%s.tsv'%(suff),'w') as OF:
for r in rateA: OF.write('%f\n'%(r))
17 Oct 2019